서버에서 데이터 가져오기 (Fetching data from the server)
- TOC {:toc}
이 글은 MDN Learn web development의 Client-side web APIs 중 Manipulating documents의 내용을 번역 및 정리한 글입니다.
- 제가 필요한 부분 위주로 확인하면서 정리하고 있어 글에 덜 작성된 부분이 있을 수 있습니다.
- 글 작성 후 원문의 내용이 수정되거나 내용을 이해하기 위한 개인적인 설명이나 해석이 있을 수 있습니다. 되도록 원문을 참고해주시길 바랍니다.
- 잘못된 부분이 있다면 댓글이나 그 외 편하신 방법으로 알려주시면 감사하겠습니다.
최신 웹사이트와 애플리케이션의 또 다른 매우 흔한 일은 개별 데이터 항목을 서버로 가져와 전체 페이지를 새로 불러올 필요 없이 웹페이지의 섹션을 갱신하는 것이다. 이 겉으로 보기에는 작은 부분이 사이트의 성능과 동작에는 큰 영향을 미치기 때문에, 이 글에서는, 해당 개념을 설명하고 이를 가능하게 하는 기술을 살펴볼 것이다: 특히, Fetch API
무엇이 문제일까? (What is the problem here?)
웹 페이지는 HTML 페이지와 (일반적으로) 스타일 시트, 스크립트, 이미지와 같은 다양한 다른 파일로 구성되어있다. 웹에서 페이지를 불러오는 기본 모델은 브라우저가 페이지를 표시하기 위해 필요한 파일을 가져오기 위해 한 개 이상의 HTTP 요청을 서버에 만들고, 서버는 요청된 파일과 함께 응답한다. 만약 다른 페이지를 방문하면, 브라우저가 새 파일을 요청하고, 서버는 이들과 함께 응답한다.

이 모델은 많은 사이트에서 완벽하게 동작한다. 하지만 데이터 중심적(data-driven)인 웹사이트를 생각해보자. 예를 들어, Vancouver Public Library와 같은 도서관 웹 사이트를 생각해보자. 이런 사이트는 무엇보다도 데이터베이스를 위한 사용자 인터페이스로 볼 수 있다. 이 사이트에서는 특정 장르의 서적을 찾거나, 이전에 빌린 책을 기반으로 좋아할 책 추천을 보여줄 수 있다. 이런 동작을 할 때, 페이지를 표시할 새로운 책 모음으로 갱신해야 한다. 하지만 대부분의 페이지 내용은 - 페이지의 헤더, 사이드바, 푸터와 같은 항목을 포함해서 - 똑같이 유지된다.
여기서 전통적인 모델의 문제는 페이지의 일부만 갱신해야 할 때도 전체 페이지를 가져와서 불러와야 했다는 것이다. 이것은 비효율적이고, 좋지 않은 사용자 경험을 만들 수 있다.
그러므로 많은 웹사이트가 전통적인 모델 대신, 서버에 데이터를 요청하고, 페이지 로드 없이 페이지 내용을 갱신하기 위해 자바스크립트 API를 사용한다. 그러므로 사용자가 새로운 제품을 찾으면, 브라우저는 페이지를 갱신해야 할 부분의 데이터만 요청한다 - 예를 들어 표시할 새로운 책 모음과 같이.

여기서 사용되는 주된 API는 Fetch API 이다. 이 API는 페이지에서 실행되는 자바스크립트가 특정 리소스를 가져오기 위한 HTTP 요청을 서버에 만들 수 있도록 해준다. 서버가 이 리소스들을 제공하면, 자바스크립트는 데이터를 사용해서 특히 DOM manipulation APIs를 사용해서, 페이지를 갱신할 수 있다. 요청된 데이터는 주로 JSON으로, 구조화된 데이터를 전송하기에 좋은 포맷이지만, HTML이나 일반 텍스트도 쓸 수 있다.
이는 Amazon, YouTube, eBay 등과 같은 데이터 중심 사이트에서 흔하게 사용하는 패턴이다. 이 모델로는:
- 페이지 업데이트가 훨씬 빨라지고, 페이지가 새로고침 될 때까지 기다릴 필요가 없다, 이는 사이트가 더 빠르고 반응적으로 느껴진다는 것을 의미한다.
- 업데이트마다 적은 데이터를 받아, 낭비되는 대역폭이 적다는 것을 의미한다. 이는 광대역(broadband)으로 연결된 데스크톱에서는 큰 문제가 아니겠지만, 모바일 기기나, 빠른 인터넷 서비스가 없는 나라에서는 중요한 문제이다.
Note: 초기에는 이 일반적인 기술이 XML 데이터를 요청하는 경향이 있어서 Asynchronous 자바스크립트와 XML(Ajax)이라고 알려졌었다. 요즘은 보통 그렇지 않지만 (아마 JSON 요청할 가능성이 더 높다), 그 결과는 여전히 같고, “Ajax”라는 용어는 여전히 이 기술을 설명하는데 자주 쓰인다.
속도를 더 높이기 위해, 일부 사이트는 자료(assets)와 데이터가 처음 요청됐을 때, 이를 사용자의 컴퓨터에 저장하기도 하는데, 이는 사용자가 다음에 사이트를 방문해 페이지가 처음 로드될 때마다 새로운 사본을 다운로드하는 대신 로컬 버전을 사용한다는 것을 의미한다. 내용은 그것이 업데이트됐을 때만 서버에서 리로드된다.
The Fetch API
Fetch API의 몇몇 예제를 살펴보자.
텍스트 콘텐츠를 가져오기 (Fetching text content)
이 예제로, 몇 개의 다른 텍스트 파일에서 데이터를 요청하고, 콘텐츠 영역을 채우기 위해 이를 사용할 것이다.
이 일련의 파일은 가짜 데이터베이스처럼 행동할 것이다; 실제 애플리케이션에서는, 데이터베이스에서 데이터를 요청하기 위해 주로 PHP, Python, Node와 같은 서버 측 언어를 사용한다. 하지만, 여기에서는, 예제를 간단하게 유지하고, 클라이언트 측 부분에만 집중하기를 원한다.
이 예제를 시작하기 위해, 컴퓨터의 새 디렉토리에 fetch-start.html와 네 텍스트 파일 - verse1.txt, verse2.txt, verse3.txt, verse4.txt - 의 로컬 복사본을 저장한다. 이 예제에서는, drop-down 메뉴에서 선택될 때 시의 다른 절(아마 잘 알 수 있는)을 가져올 것이다.
<script> 요소 안에, 다음의 코드를 추가하자. 이 코드는 <select>와 <pre> 요소의 참조를 저장하고, <select> 요소에 리스너를 추가해, 사용자가 새로운 값을 선택하면, 새 값이 updateDisplay() 함수의 매개변수로 전달된다.
const verseChoose = document.querySelector('select');
const poemDisplay = document.querySelector('pre');
verseChoose.addEventListener('change', () => {
const verse = verseChoose.value;
updateDisplay(verse);
});
updateDisplay() 함수를 정의해보자. 우선, 이전의 코드 블록 아래에 다음을 입력하자 - 이는 함수의 빈 껍데기(shell)이다.
function updateDisplay(verse) {
}
위 함수를 나중에 필요할 때 로드하려는 텍스트 파일을 가리키는 상대 경로(URL)를 구성하는 것으로 함수를 작성하기 시작할 것이다. <select> 요소의 값은 선택한 <option>의 텍스트와 항상 동일하다 (값 속성에서 다른 값을 지정하지 않는 한) - 그러므로 예를 들어 “Verse 1”. 해당 구절 텍스트 파일은 “verse1.txt”이며 HTML과 동일한 디렉토리에 있으므로, 파일 이름만 작성하면 된다.
그러나, 웹 서버는 대소문자를 구분하는 경향이 있고, 파일 이름은 공백을 포함하지 않는다. “Verse 1”을 “verse1.txt”로 바꾸기 위해서는 V를 소문자로 바꾸고, 공백을 제거한 뒤, .txt를 끝에 추가해야 한다. 이 작업은 replace(), toLowerCase(), 문자열 결합으로 완료할 수 있다. 다음의 코드를 updateDisplay() 함수 안에 추가해야 한다:
verse = verse.replace(' ', '').toLowerCase();
const url = `${verse}.txt`;
마침내, Fetch API를 사용하기 위한 준비가 되었다:
// fetch()를 호출해 URL을 전달한다.
fetch(url)
// fetch()는 promise를 반환한다. 서버에서 응답을 수신할 때,
// promise의 then() 핸들러가 응답과 함께 호출된다.
.then( response => {
// 핸들러는 요청이 성공하지 못하면 오류를 던진다.
if (!response.ok) {
throw new Error(`HTTP error: ${response.status}`);
}
// 그렇지 않으면 (응답이 성공적이면), 핸들러가 response.text()를 호출해
// 응답을 텍스트로 가져오고, response.text()에 의해 반환된 promise를
// 바로 반환한다.
return response.text();
})
// response.text()가 성공하면, then() 핸들러가 텍스트와 함께
// 호출되고, 이를 poemDisplay 박스에 복사한다.
.then( text => poemDisplay.textContent = text )
// 발생할 수 있는 오류를 탐지하고 poemDisplay 박스에
// 메시지를 표시한다.
.catch( error => poemDisplay.textContent = `Could not fetch verse: ${error}`);
이 안에는 풀어야(unpack) 할 것들이 꽤 많다.
먼저, Fetch API의 진입점은 fetch()라고 불리는 전역 함수로, URL을 매개변수로 받는다 (사용자 정의 설정을 위한 두 번째 추가 매개변수를 받지만, 여기서는 사용하지 않는다).
다음으로, fetch()는 Promise를 반환하는 비동기적 API이다. Promise가 무엇인지 모르면, 비동기 자바스크립트의 모듈, 특히 promises의 글을 읽고 여기로 돌아오자. 해당 글도 fetch() API에 대해서 얘기하고 있다는 것을 발견할 수 있다!
그래서 fetch()가 promise를 반환하므로, 반환된 promise의 then() 함수로 함수를 전달한다. 이 함수는 HTTP 요청이 서버에서 응답을 받을 때 호출된다. 핸들러에서는, 요청이 성공적인지 확인하고, 만약 그러지 않으면 오류를 던진다. 그렇지 않으면 응답 본문(body)을 텍스트로 가져오기 위해 response.text()를 호출한다.
response.text()도 비동기적이라, response.text()가 반환하는 promise를 반환하고, 이 새 promise의 then() 함수에 함수를 전달한다. 이 함수는 응답 텍스트가 준비되면 호출되고, 그 안에서 <pre> 블록을 해당 텍스트로 업데이트한다.
마지막으로, 호출한 비동기 함수나 이들의 처리기에서 발생한 오류를 잡기 위해 catch() 핸들러를 마지막에 연결한다.
이 예제의 한 가지 문제는 처음 로드됐을 때, 어떤 시도 보여주지 않는다는 것이다. 이를 고치기 위해서, verse 1을 기본으로 불러오고, <selct> 요소가 항상 올바른 값을 보여주도록 하고 싶다면 다음의 두 줄을 코드의 마지막(닫는 </script> 태그 바로 위에)에 추가하자:
updateDisplay('Verse 1');
verseChoose.value = 'Verse 1';
서버에서 예제를 실행하기 (Serving your example from a server)
만약 예제를 로컬 파일에서 실행하면 최신 브라우저는 HTTP 요청을 실행하지 않을 것이다. 이는 보안 제한 (더 많은 웹 보안을 알기 위해서는, 웹사이트 보안을 읽어보자) 때문이다.
이 문제를 해결하기 위해서, 로컬 웹 서버에서 실행해 예제를 테스트해야 한다. 이걸 하는 방법을 알기 위해서는 로컬 테스트 서버를 설정하는 가이드를 읽어보자.
통조림 가게 (The can store)
이 예제에서는 통조림 가게라고 불리는 샘플을 만들 것이다 - 통조림만 파는 가상의 슈퍼마켓이다. 이 실제 실행 예제를 GitHub에서 찾을 수 있고, 소스 코드를 봐보자
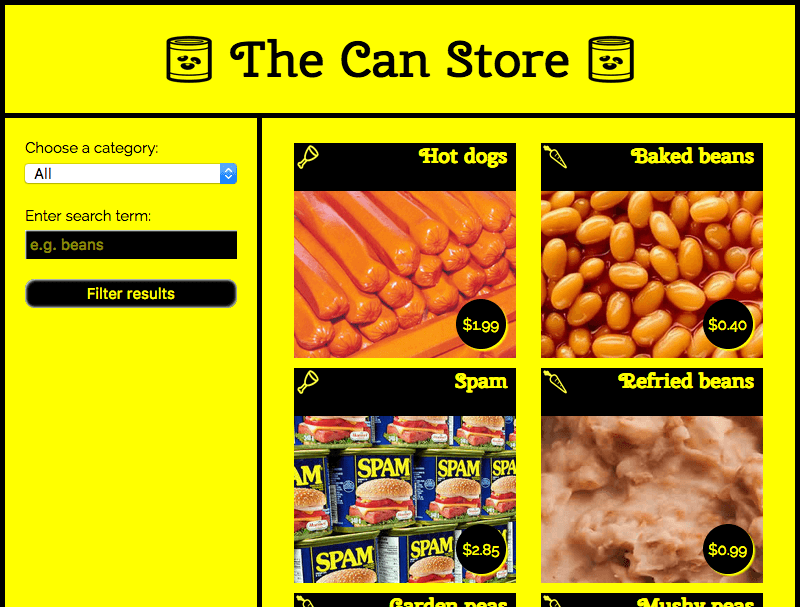
기본적으로, 사이트는 모든 제품을 표시하지만, 왼쪽 열의 양식 컨트롤을 사용해 카테고리 또는 검색어 별로 필터링할 수 있다.
카테고리와 검색어로 제품을 필터링하고 문자열을 조작하여 데이터가 UI에서 올바르게 표시되도록 하는 등 복잡한 코드가 꽤 많다. 모든 것을 이 글에서 논의하진 않지만, 코드에서 상세한 주석을 볼 수 있다 (can-script.js를 보자).
하지만 Fecth 코드는 설명할 것이다.
Fetch를 사용하는 첫 번째 블록은 자바스크립트의 처음에서 찾을 수 있다:
fetch('products.json')
.then( response => {
if (!response.ok) {
throw new Error(`HTTP error: ${response.status}`);
}
return response.json();
})
.then( json => initialize(json) )
.catch( err => console.error(`Fetch problem: ${err.message}`) );
fetch() 함수는 promise를 반환한다. 만약 함수가 성공적으로 완성되면, .then() 블록 안의 첫 번째 함수가 네트워크에서 반환된 response를 포함한다.
이 함수 안에서는:
- 서버가 (404 Not Found와 같은) 오류를 반환하지 않는지 확인한다. 만약 반환하면 오류를 던진다.
- 응답에서
json()을 호출한다. 이는 데이터를 JSON 객체로 가져온다.response.json()에 의해 반환된 promise를 반환한다.
다음으로 함수를 반환된 promise의 then() 메소드에 전달한다. 이 함수는 응답 데이터를 포함한 객체를 JSON으로 전달하며, 이를 initialize() 함수로 전달한다. 이 함수는 모든 제품을 사용자 인터페이스에 표시하는 프로세스를 시작한다.
오류를 처리하기 위해서, .catch() 블록을 체인 마지막에 연결한다. 이것은 promise가 어떤 이유로 실패하면 실행된다. 이 안에는, 매개변수로 전달되는 함수와, err 객체가 포함된다. err 객체는 오류가 발생한 환경을 보고하는데 사용될 수 있는 객체로, 이 경우 간단한 console.log()로 수행한다.
완전한 웹사이트는 사용자의 화면에 메시지를 표시하고 아마 상황을 해결할 수 있는 옵션을 제공해 이 오류를 더 우아하게 처리할 수 있지만, 여기서는 간단한 console.error() 이상은 필요하지 않다.
실패하는 경우를 스스로 만들어(test)볼 수 있다:
- 예제 파일의 로컬 복사본을 만든다.
- 웹 서버를 통해 코드를 실행한다 (위의 서버에서 예제를 실행하기에서 언급한 것처럼).
- 파일을 불러오는 경로를 ‘produc.json’과 같은 것으로 수정한다 (철자가 확실히 틀렸는지 확인하자).
- 브라우저에 인덱스 파일을 불러오고 (
localhost:8000을 통해) 브라우저 개발자 콘솔을 살펴보자. “Fetch problem: HTTP error: 404”와 비슷한 오류 메시지를 볼 것이다.
두 번째 Fetch 블록은 fetchBlob() 함수 안에서 발견할 수 있다:
fetch(url)
.then( response => {
if (!response.ok) {
throw new Error(`HTTP error: ${response.status}`);
}
return response.blob();
})
.then( blob => showProduct(blob, product) )
.catch( err => console.error(`Fetch problem: ${err.message}`) );
이것은 json을 사용하는 대신 blob()을 사용한다는 것을 제외하고는, 이전과 굉장히 비슷한 방식으로 작동한다. 이 경우에는 응답을 이미지 파일로 반환하기를 원하고, 이를 위해 사용하는 데이터 포맷은 Blob(이 용어는 “Binary Large Object”의 줄임말이고 기본적으로 이미지나 비디오 파일처럼 크기가 큰 파일과 유사한 객체를 나타내는 데 사용된다)이다.
blob을 성공적으로 수신하면, 이를 표시하는 showProduct() 함수에 수신한 blob을 전달한다.
The XMLHttpRequest API
때때로, 특히 오래된 코드에서는, HTTP 요청을 만드는 데 사용하는 XMLHttpRequest(주로 “XHR”으로 축약한다)라는 또 다른 API를 볼 수 있다. 이 이전 버전(predated)의 Fetch는 AJAX를 구현하는데 널리 사용되는 첫 번째 API였다. 가능하다면 Fetch를 사용하는 것을 권장한다: 더 간단한 API이고 XMLHttpRequest보다 더 많은 기능을 갖는다. XMLHttpRequest를 사용하는 예제는 다루지 않지만, 첫 번째 통조림 저장 요청의 XMLHttpRequest 버전은 어떻게 보이는지 보여줄 것이다:
const request = new XMLHttpRequest();
try {
request.open('GET', 'products.json');
request.responseType = 'json';
request.addEventListener('load', () => initialize(request.response));
request.addEventListener('error', () => console.error('XHR error'));
request.send();
} catch(error) {
console.error(`XHR error ${request.status}`);
}
여기에는 다섯 단계가 있다:
- 새로운
XMLHttpRequest객체를 만든다. - 객체의
open()메소드를 호출해 이를 초기화한다. - 객체의 응답이 성공적으로 완료됐을 때 호출되는
load이벤트에 이벤트 리스너를 추가한다. 리스너 안에서는 데이터와 함께initialize()를 호출한다. - 요청이 오류를 마주치면 호출되는
error이벤트에 이벤트 리스터를 추가한다. - 요청을 보낸다.
또한 open()이나 send()가 던진 오류를 처리하기 위해 모든 것을 try … catch 블록으로 감싸야 한다.
바라건대, Fetch API가 이것을 개선한 것으로 생각하길 바란다. 특히, 두 곳의 오류를 어떻게 처리해야 하는지 살펴보자.
-
draft