Chapter 20. 최소 신장 트리의 이해: 크루스칼 알고리즘(Kruskal's Algorithm)
- TOC {:toc}
이 글은 패스트 캠퍼스 기술면접 완전 정복 올인원 패키지 Online ‘Chapter 20. 최소 신장 트리의 이해: 크루스칼 알고리즘(Kruskal’s Algorithm)’의 강의내용을 정리하기 위해 강의 자료를 기반으로 작성한 글입니다.
강의 노트는 강의 구매자에게만 제공되는 자료이긴 하지만 잔재미 코딩의 6. 최소 신장 트리 (Kruskal Algorithm)에서 동일한 자료를 제공하고 있기 때문에 해당 자료를 기반으로 정리한 글을 작성해서 올립니다. 혹시 문제가 되는 경우 바로 내릴 예정이니 알려주시면 감사하겠습니다.
내용을 이해하기 위한 개인적인 설명이나 해석이 있을 수 있기 때문에 되도록 원문을 참고해주시길 바랍니다. 잘못된 부분이 있다면 댓글이나 그 외 편하신 방법으로 알려주시면 감사하겠습니다.
1. 신장 트리란?
- Spanning Tree, 또는 신장 트리라고 불림 (Spanning Tree가 더 자연스러워 보임)
- 원래의 그래프의 모든 노드가 연결되어 있으면서 트리의 속성을 만족하는 그래프
신장 트리의 조건
- 본래의 그래프의 모든 노드를 포함해야 함
- 모든 노드가 서로 연결
- 트리의 속성을 만족시킴 (사이클이 존재하지 않음)
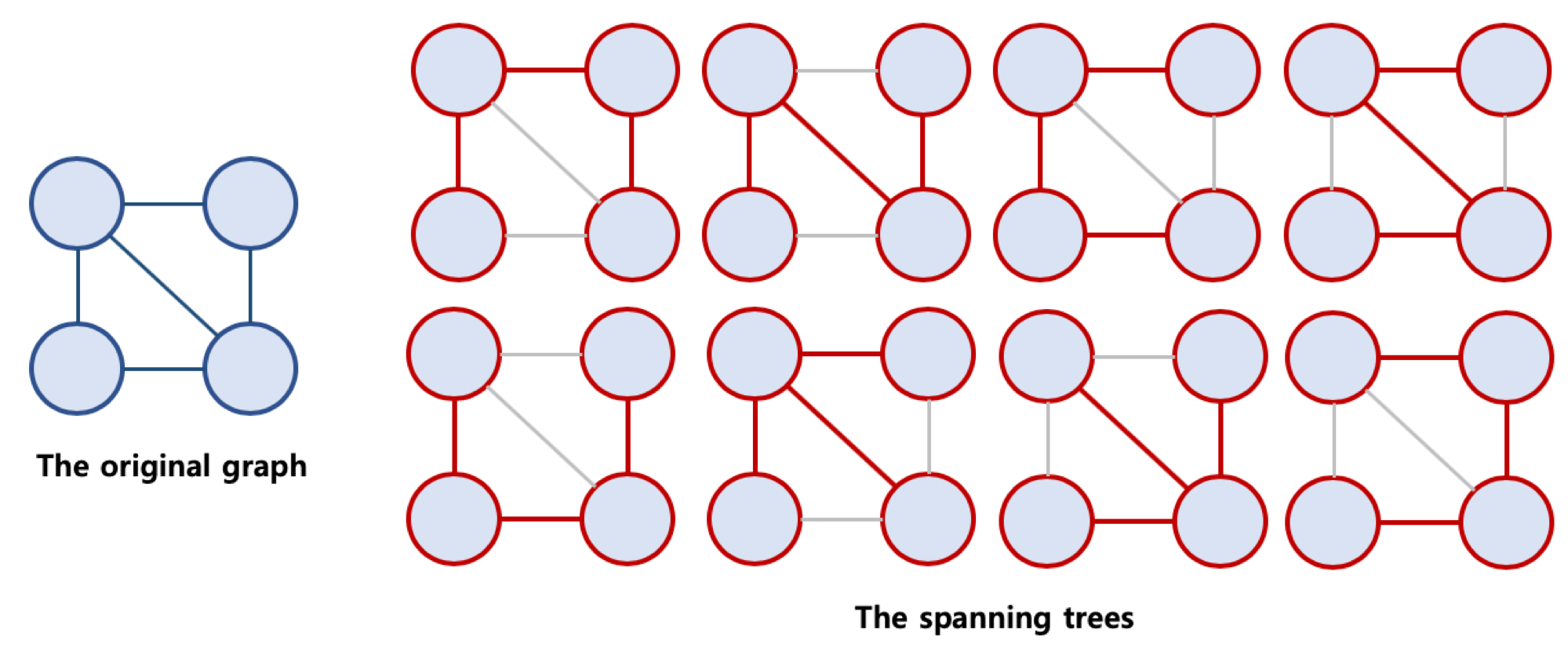
2. 최소 신장 트리
- Minimum Spanning Tree, MST 라고 불림
- 가능한 Spanning Tree 중에서, 간선의 가중치 합이 최소인 Spanning Tree를 지칭함
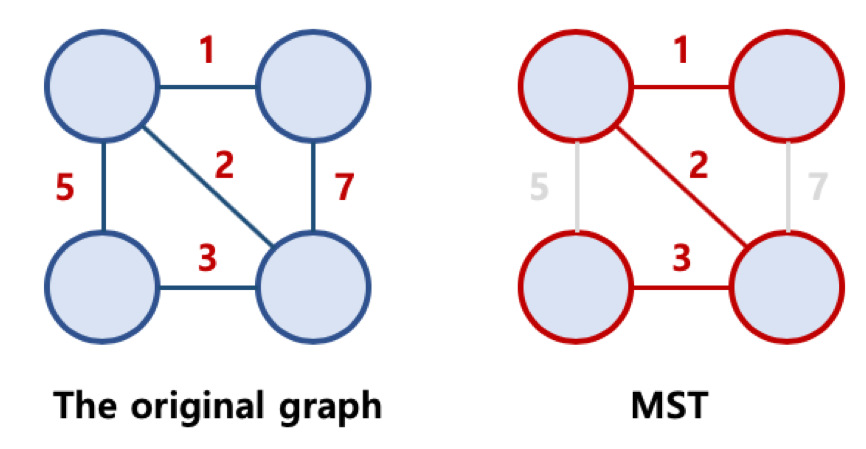
3. 최소 신장 트리 알고리즘
- 그래프에서 최소 신장 트리를 찾을 수 있는 알고리즘이 존재함
- 대표적인 최소 신장 트리 알고리즘
- Kruskal’s algorithm (크루스칼 알고리즘), Prim’s algorithm (프림 알고리즘)
4. 크루스칼 알고리즘 (Kruskal’s algorithm)
- 모든 정점을 독립적인 집합으로 만든다.
- 모든 간선을 비용을 기준으로 정렬하고, 비용이 작은 간선부터 양 끝의 두 정점을 비교한다.
- 두 정점의 최상위 정점을 확인하고, 서로 다를 경우 두 정점을 연결한다. (최소 신장 트리는 사이클이 없으므로, 사이클이 생기지 않도록 하는 것임)
탐욕 알고리즘을 기초로 하고 있음 (당장 눈앞의 최소 비용을 선택해서, 결과적으로 최적의 솔루션을 찾음)
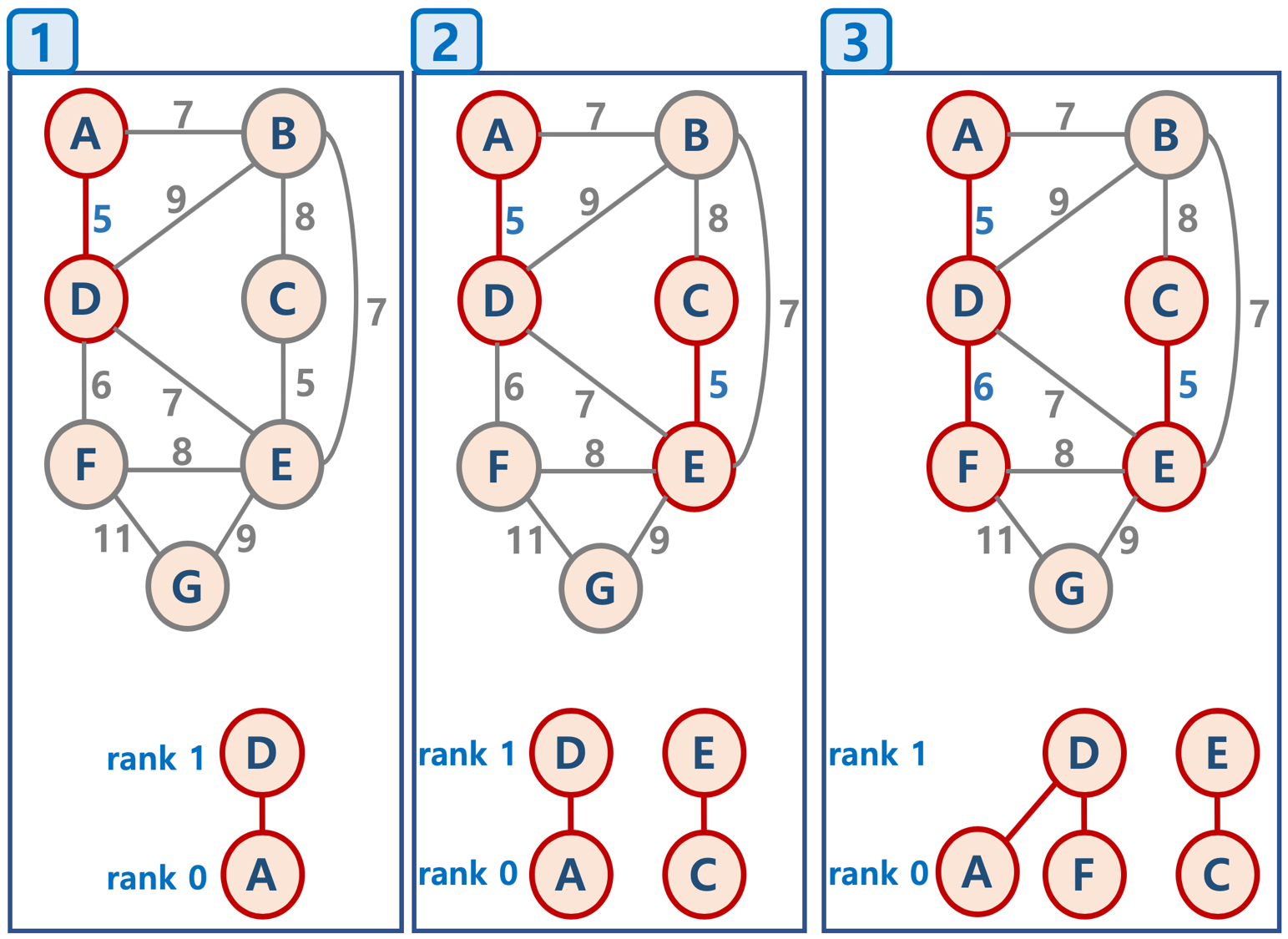
위 그림의 진행 과정은 다음과 같다. 붉은색이 지금까지 연결된 노드와 간선을 나타낸다.
- 가중치가 최솟값(5)인 A - D를 연결한다.
- 동일한 가중치(5)를 갖는 C - E를 연결한다. 1번과 순서는 상관 없다.
- 다음으로 가중치가 작은(6) D - F를 연결한다.
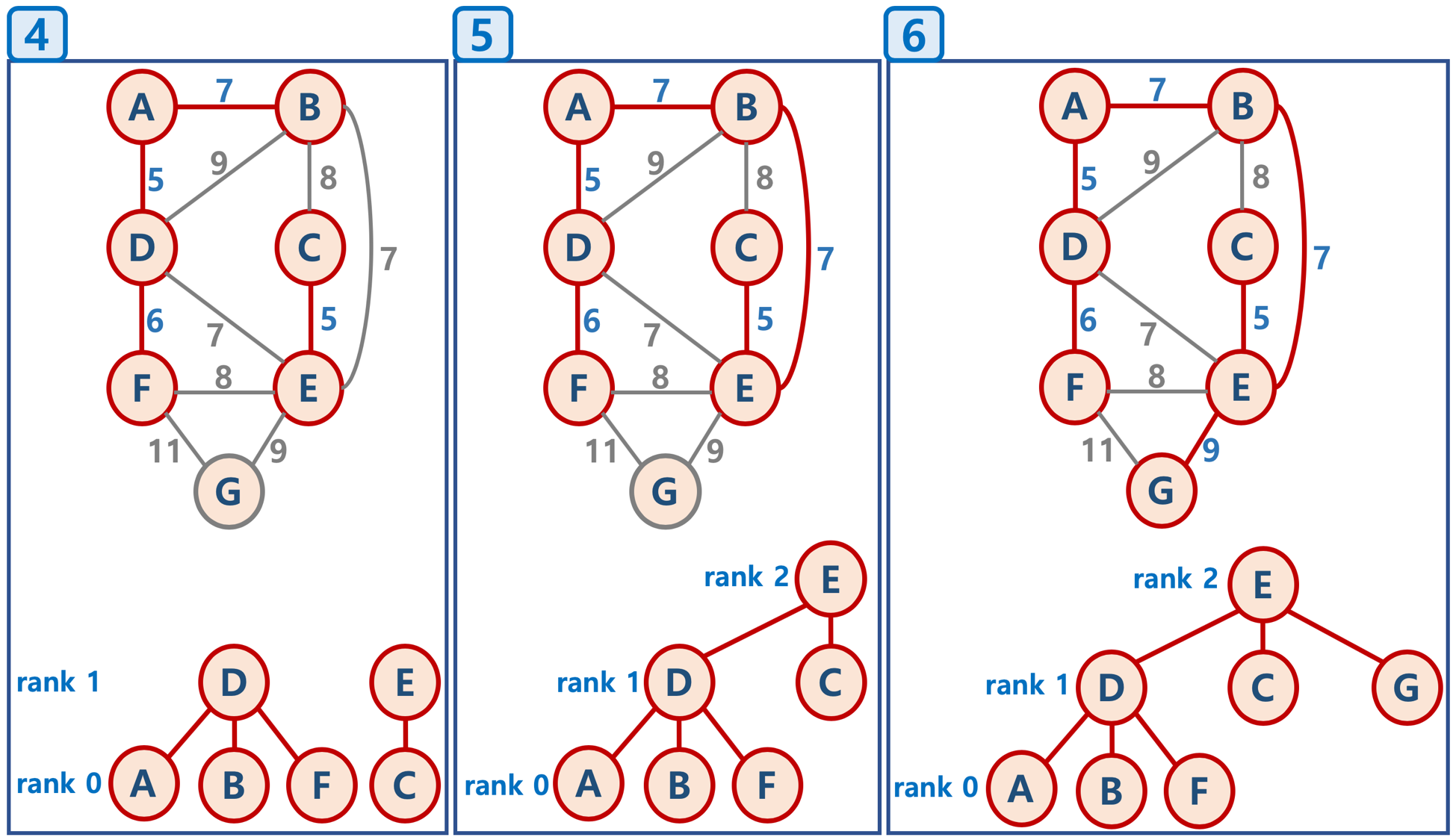
- 다음으로 가중치가 작은(7) A - B를 연결한다.
- 동일한 가중치(7)를 갖는 B - E를 연결한다.
- D - E의 가중치도 7이지만 연결하면 사이클이 생성되기 때문에 연결하지 않는다.
- 마지막으로 가중치 9의 G - E를 연결하면 모든 노드가 연결되고 실행을 끝낸다.
- 5번(B - E) 다음으로 가중치가 작은 노드는 가중치 8의 B - C, F - E이지만 둘 다 연결하면 사이클이 생성되므로 연결하지 않는다.
- B - D 역시 가중치가 9이지만 연결하면 사이클이 생성되므로 연결하지 않는다.
5. Union-Find 알고리즘
크루스칼 알고리즘에서 사이클을 체크하는 과정이 가장 어렵고, 이를 위한 다양한 알고리즘이 있다.
대표적인 알고리즘이 Union-Find 알고리즘이다.
- Disjoint Set을 표현할 때 사용하는 알고리즘으로 트리 구조를 활용하는 알고리즘
- 간단하게, 노드 중에 연결된 노드를 찾거나, 노드들을 서로 연결할 때 (합칠 때) 사용
크루스칼 알고리즘에서 사이클이 생기는 걸 방지하기 위해 두 정점의 최상위 정점을 확인하는 단계가 Union-Find 알고리즘에 해당한다.
- 예를 들어 위 예시의 5번 단계에서 지금까지 연결된 노드를 하나의 집합으로 생각해보자. S = {F, D, A, B, E, C}
- 그래프 내의 두 노드를 연결하려고 할 때 두 노드가 모두 위의 집합에 속해있으면 두 노드를 연결할 때 사이클이 생긴다.
- D - E를 연결하려고 할 때 D, E 모두 S 안의 원소이기 때문에 연결하면 사이클이 생긴다.
- 이를 피하기 위해서는 연결하려는 노드의 최상단 노드를 확인하면 된다.
- 아래 트리 구조에서 D의 최상단 노드는 E로 E와 동일하기 때문에 연결하면 안 된다는 것을 알 수 있다.
Disjoint Set이란
- 서로 중복되지 않는 부분 집합들로 나눠진 원소들에 대한 정보를 저장하고 조작하는 자료구조
- 공통 원소가 없는 (서로소) 상호 배타적인 부분 집합들로 나눠진 원소들에 대한 자료구조를 의미함
- Disjoint Set = 서로소 집합 자료구조
Union-Find 알고리즘
- 초기화
- n 개의 원소가 개별 집합으로 이뤄지도록 초기화

- Union
- 두 개별 집합을 하나의 집합으로 합침, 두 트리를 하나의 트리로 만듦
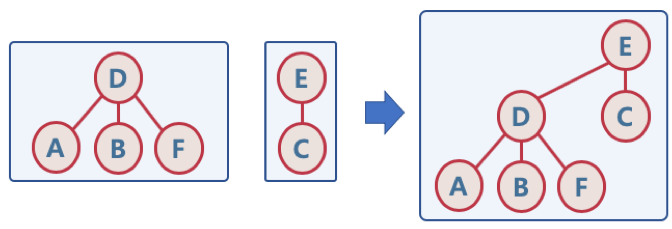
- E를 전체의 루트 노드로 놓고 D를 E의 자식 노드로 넣음.
- Find
- 여러 노드가 존재할 때, 두 개의 노드를 선택해서, 현재 두 노드가 서로 같은 그래프에 속하는지 판별하기 위해, 각 그룹의 최상단 원소 (즉, 루트 노드)를 확인
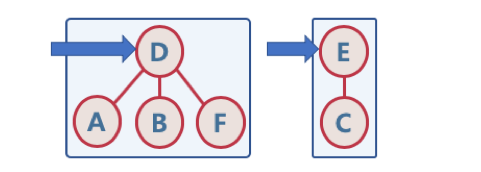
- A - E가 같은 보려면 D와 E를 확인해야 한다.
Union 과정(트리를 어떻게 구성하는가)과 Find 과정(루트 노드를 어떻게 찾는가)을 어떻게 하는가에 따라서 성능의 차이가 크게 날 수 있다.
Union-Find 알고리즘의 고려할 점
- Union 순서에 따라서, 최악의 경우 링크드 리스트와 같은 형태가 될 수 있음.
- 이때는 Find/Union 시 계산량이 $O(N)$ 이 될 수 있으므로, 해당 문제를 해결하기 위해, union-by-rank, path compression 기법을 사용함
union-by-rank 기법
- 각 트리에 대해 높이(rank)를 기억해 두고,
- Union시 두 트리의 높이(rank)가 다르면, 높이가 작은 트리를 높이가 큰 트리에 붙임 (즉, 높이가 큰 트리의 루트 노드가 합친 집합의 루트 노드가 되게 함)
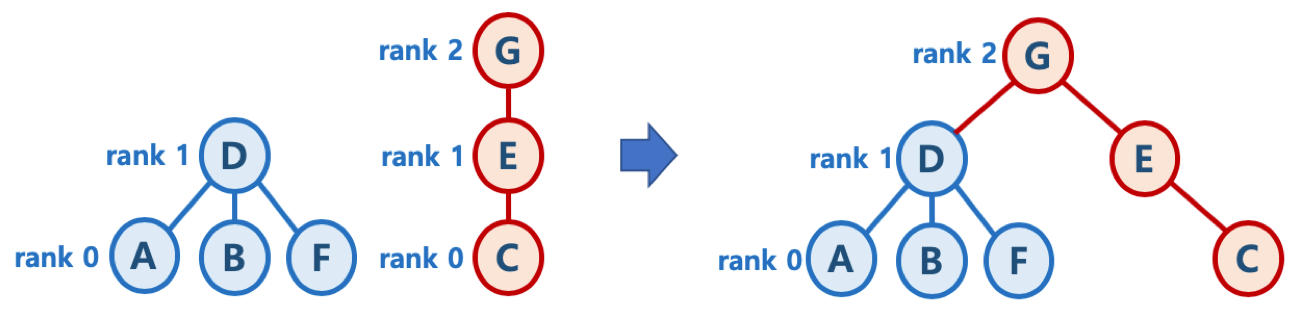
- 높이가 h - 1인 두 개의 트리를 합칠 때는 한쪽의 트리 높이를 1 증가시켜주고, 다른 쪽의 트리를 해당 트리에 붙여줌
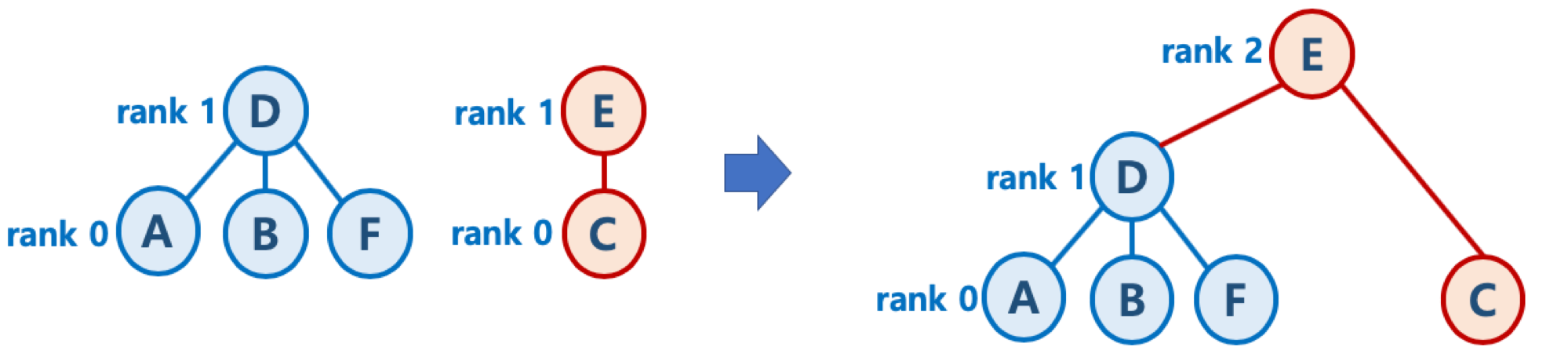
초기화시, 모든 원소는 높이(rank) 가 0인 개별 집합인 상태에서, 하나씩 원소를 합칠 때, union-by-rank 기법을 사용한다면,
- 높이가 h인 트리가 만들어지려면, 높이가 h - 1인 두 개의 트리가 합쳐져야 함
- 높이가 h - 1인 트리를 만들기 위해 최소 n개의 원소가 필요하다면, 높이가 h인 트리가 만들어지기 위해서는 최소 2n 개의 원소가 필요함
- 따라서 union-by-rank 기법을 사용하면, union/find 연산의 시간복잡도는 $O(N)$ 이 아닌, $O(\log N)$로 낮출 수 있음
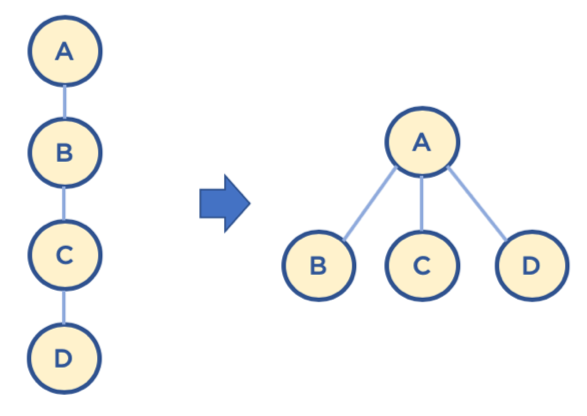
path compression
- Find를 실행한 노드에서 거쳐 간 노드를 루트에 다이렉트로 연결하는 기법
- Find를 실행한 노드는 이후부터는 루트 노드를 한 번에 알 수 있음
union-by-rank 와 path compression 기법 사용 시 시간 복잡도는 다음 계산식을 만족함이 증명되었음
- $O(M\log ^\ast N)$
- $\log ^\ast N$은 다음 값을 가짐이 증명되었음
- $N$이 $2^{65536}$ 값을 가지더라도, $\log ^\ast N$의 값이 5의 값을 가지므로, 거의 $O(1)$, 즉 상숫값에 가깝다고 볼 수 있음
| $N$ | $O(\log ^\ast N)$ |
|---|---|
| 1 | 0 |
| 2 | 1 |
| 4 | 2 |
| 16 | 3 |
| 65536 | 4 |
| $2^{65536}$ | 5 |
6. 크루스칼 알고리즘 (Kruskal’s algorithm) 코드 작성
# 그래프
mygraph = {
'vertices': ['A', 'B', 'C', 'D', 'E', 'F', 'G'],
'edges': [
(7, 'A', 'B'),
(5, 'A', 'D'),
(7, 'B', 'A'),
(8, 'B', 'C'),
(9, 'B', 'D'),
(7, 'B', 'E'),
(8, 'C', 'B'),
(5, 'C', 'E'),
(5, 'D', 'A'),
(9, 'D', 'B'),
(7, 'D', 'E'),
(6, 'D', 'F'),
(7, 'E', 'B'),
(5, 'E', 'C'),
(7, 'E', 'D'),
(8, 'E', 'F'),
(9, 'E', 'G'),
(6, 'F', 'D'),
(8, 'F', 'E'),
(11, 'F', 'G'),
(9, 'G', 'E'),
(11, 'G', 'F')
]
}
# 각 노드의 부모 노드를 저장
parent = dict()
# 각 노드의 rank 값을 저장 (union by rank)
rank = dict()
# 루트 노드를 찾는 함수
def find(node):
# path compression 기법
# 자기 자신이 루트 노드인 노드인
# 루트 노드에 도달할 때까지
if parent[node] != node:
# 부모 노드에 대해 find 함수를 재귀적으로 호출해
# 현재 부모 노드를 함수 반환 값으로 바꾼다.
parent[node] = find(parent[node])
# 루트 노드에 도달하면 해당 노드를 반환한다.
return parent[node]
# 즉, 현재 노드에서 루트 노드로 가는 경로의 모든 노드의 부모 노드를
# 루트 노드로 바꾼다.
# 두 노드를 포함하고 있는 노드 집합을 연결하는 함수
def union(node_v, node_u):
# 입력받은 노드의 루트 노드를 구한다.
root1 = find(node_v)
root2 = find(node_u)
# union-by-rank 기법
# root 1의 랭크가 root 2보다 크면
if rank[root1] > rank[root2]:
# root 2의 부모 노드를 root 1로 바꾼다.
parent[root2] = root1
# 반대의 경우에는
else:
# root 1의 부모 노드를 root 2로 바꾼다.
parent[root1] = root2
# 만약 두 root의 랭크가 같으면
if rank[root1] == rank[root2]:
# root 2의 랭크를 1 높인다.
# (위에서 root 1을 root 2로 연결했기 때문에)
rank[root2] += 1
# 초기화 함수
def make_set(node):
# 부모 노드가 없는 상태이므로 자신을 부모 노드로 지정
parent[node] = node
# rank는 0으로 지정
rank[node] = 0
def kruskal(graph):
mst = list()
# 1. 초기화
for node in graph['vertices']:
make_set(node)
# 2. 간선 weight 기반 sorting
edges = graph['edges']
edges.sort()
# 3. 간선 연결 (사이클 없는)
for edge in edges:
weight, node_v, node_u = edge
# 현재 두 노드의 루트 노드를 찾아서
# 두 노드가 다르면 (사이클을 이루지 않음)
if find(node_v) != find(node_u):
# 두 노드가 포함된 부분집합을 합친다.
union(node_v, node_u)
# mst에 해당 edge를 추가.
mst.append(edge)
return mst
kruskal(mygraph)
# 출력 결과
# 최소 신장 트리를 이루고 있는 연결된 간선 목록
# [(5, 'A', 'D'),
# (5, 'C', 'E'),
# (6, 'D', 'F'),
# (7, 'A', 'B'),
# (7, 'B', 'E'),
# (9, 'E', 'G')]
7. 시간 복잡도
크루스컬 알고리즘의 시간 복잡도는 $O(E\log E)$
- 다음 단계에서 2번, 간선을 비용 기준으로 정렬하는 시간에 좌우됨 (즉 간선을 비용 기준으로 정렬하는 시간이 가장 큼)
- 모든 정점을 독립적인 집합으로 만든다.
- 모든 간선을 비용을 기준으로 정렬하고, 비용이 작은 간선부터 양 끝의 두 정점을 비교한다.
- 퀵소트를 사용한다면 시간 복잡도는 $O(n\log n)$ 이며, 간선이 n이므로 $O(E \log E)$
- 두 정점의 최상위 정점을 확인하고, 서로 다를 경우 두 정점을 연결한다. (최소 신장 트리는 사이클이 없으므로, 사이클이 생기지 않도록 하는 것임)
- union-by-rank 와 path compression 기법 사용 시 시간 복잡도가 결국 상숫값에 가까움, $O(1)$
